TrueType入门:基本概念
OpenType是TrueType的扩展。本文全流程介绍TrueType从字体设计到字体显示的每个步骤,这些步骤同样也适用于OpenType。
TrueType字体可能诞生于纸上,也可能从其他格式转换而来。但最终,字体文件中一定包含每个字形的描述信息。下图展示了从设计稿原件到数字化字形,再到字体文件中数字化轮廓的过程。
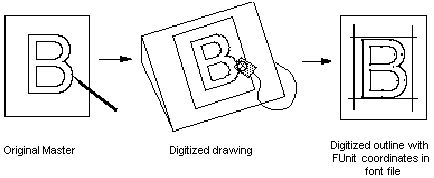
图1 设计稿原件、数字化字形、字体文件中以FUnit坐标表示的数字化轮廓
那么TrueType字体是如何在显示设备(屏幕、打印机)上应用的呢?
首先,要将字体文件中存储的轮廓缩放到要求的尺寸,即将字体文件中以FUnit(Font Uint,字体单位)表示的原始轮廓转换为特定于设备的像素坐标。
然后,解释器运行与字形关联的指令,运行指令的结果是完成字形的网格适配(grid-fit)。完成网格适配,再由扫描转换程序生成最张在目标设备上呈现的位图图像。
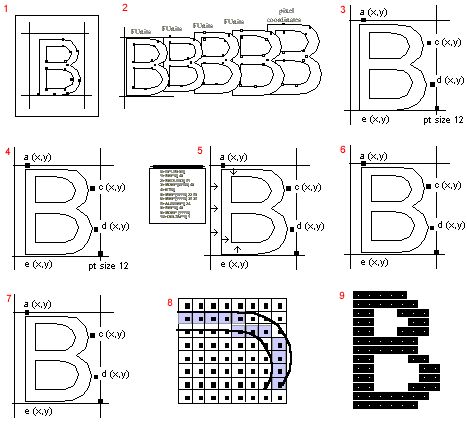
图2 字体渲染流程
- 在TrueType字体文件中以FUnit坐标形式描述字形的轮廓
- 缩放程序将FUnit转换为像素坐标,并缩放至应用程序要求的大小
- 轮廓缩放至新网格
- 缩放后以像素坐标表示的轮廓
- 解释程序执行与字形B关联的指令,进行网格适配
- 网格适配后的轮廓
- 网格适配后的轮廓
- 扫描转换器决定打开哪些像素
- 在目标设备上渲染位置
字形数字化
字体中所包含字形的轮廓是以连续的点来表示的,这些点位于一个虚拟的坐标系中。
轮廓
在TrueType字体中,字形的形状由轮廓(contour)来表示,而轮廓由位于虚拟坐标上的点来表示。简单的字形可能只有一个轮廓,复杂的字形则有多个轮廓。而复合字形则可以由多个简单的字形组合而成。字体文件中,那些没有可见外形的控制字符都会映射到没有轮廓的字形。
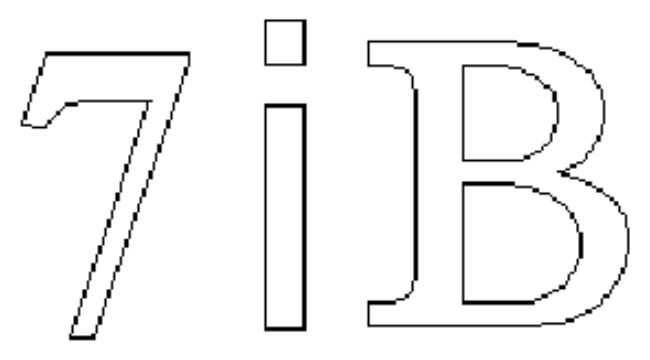
图3 包含1个、2个和3个轮廓的字形
轮廓由直线和曲线组成。曲线由描述二阶贝塞尔曲线的一系列点定义。TrueType的贝塞尔曲线格式使用两种点定义曲线:线上点(on)和线下点(off)。直线由两个连续的线上点定义。
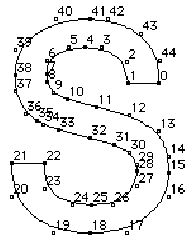
图3 由一系列线上点和线下点构成的字形
构成曲线的点必须以连续的数值编号,编号是升序还是降序也很重要,因为它决定构成字形的形状的填充模式。总之,如果曲线是沿着升序编号定义,则黑空间即填充区始终在右侧。
FUnit与em方块
在TrueType字体文件中,点的位置以字体单位或FUnit表示。所谓FUnit,就是em方块中最小的度量单位,而em方块则是用于衡量字形大小以及对齐字形的一个虚拟方块。通常,一个字形的em方块包含字形的全身长,再加上排版时没有额外铅空条件下避免行与行过于拥挤的额外空间。
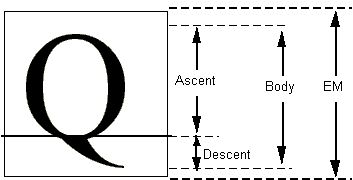
图5 em方块
在金属字模的时代,字形不会伸出em方块,但数字字体没有这些限制。em方块可以做得足够大,以包含所有字形,包括注音的字形。不过,在必要的时候,有的字形也可以伸出em方。TrueType字体支持这两种情形,具体使用哪种由字体制造商决定。

图6 伸出em方块的字形
em方块定义了一个二维坐标网络系统,其中x轴表示水平方向的移动,y轴表示垂直方向的移动。
FUnit与网格
字体数字化,首先要确定描述字形轮廓的点,其精确度或者解析度如何。这些点的精确度由em网格最小的可度量长度,也就是FUnit决定。这个网格在一个二维的坐标系里,坐标原点是(0, 0)。但这个网格不是无穷平面,而是位于-16384到+16384 FUnit之间。FUnit大小的选择不同,网格中点的数量也多寡不同。
每个em网格中包含的FUnit数量,也就是upem(FUnit per Em)由字体设计者或制造商决定。不过,将upem设定为2的整数次幂,比如2048,可以让轮廓缩放时速度最快。
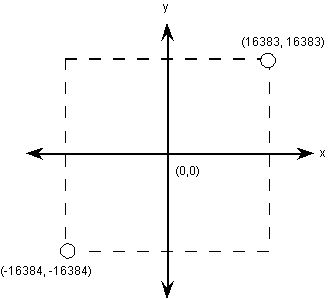
图7 em方块中的网格坐标系
em方块中的坐标原点放在哪里并没有一定之规。实践中,通常要遵循一些惯例。比如,Roman字体用于水平排版,那么其y坐标的0值通常放在字体的基线上。至于x坐标的0值放在哪里就很自由了。只不过选择惯常的做法有可能性能更好。
比如,对于用于竖排版的字体,选择字形的视觉中心点作为x轴原点可以让字形排列起来更美观。而用于水平排版的字体,也可以让字体轮廓最左端那个点的x值等于字形左边空(left-side-bearing)。这样的字体在PostScript打印机中打印速度更快。
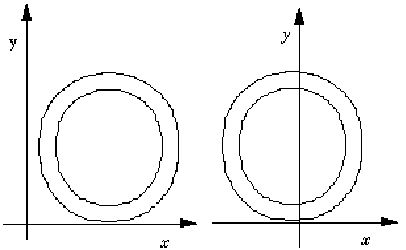
图8 两种字形原点选择:左边是字形左边空的x值为0,右边是视觉中心的x值为0
接下来,每个em方块中包含的FUnit数量也就是upem决定了em方块的粒度。upem越大,精度越高。
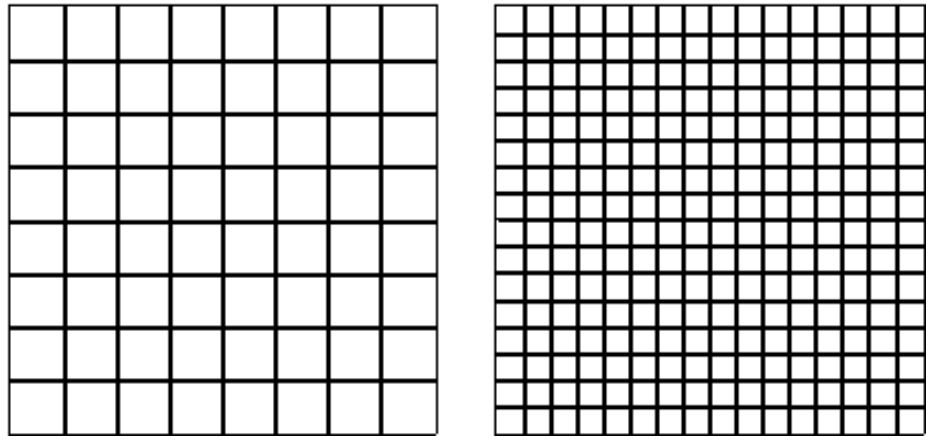
图9 两个em方块的网格:左侧每em包含8个单位,右侧每em包含16个单位
FUnit是一个相对单位,因为其实际代表的大小会随着em方块的大小而变化。但每em中包含的FUnit数量,即upem则一个常量,无论字形最终被渲染为多大都不会变。说到最终渲染,就又有了一个概念:ppem,即每em方块对应的点数。这里的点(point)是一个绝对大小单位,即1点=1/72英寸=0.353毫米。如果一个字形被渲染为9点大,那么每个em方块就包含9点(9×0.353=3.17毫米),被渲染为14点大,每个em方块就是包含14点(14×0.353=4.94毫米)。既然upem不变,而ppem会变,那么FUnit在渲染时对应的绝对大小自然也会变化。
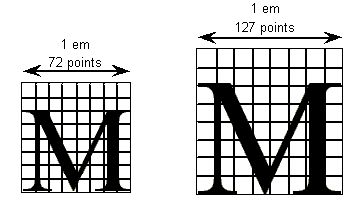
图10 72点的M和127点的M及它们的em方块,两种情况下的upem都是8
换句话说,无论字体被渲染为多大,以FUint为单位的upem始终不会变。
缩放字形
下面我们来看看字体文件中的字形轮廓是怎么缩放为应用程序所要求的大小的。
设备空间
无论字形轮廓以多大的精度来定义,在最终打印或显示字形之前都必须经过缩放,以适应输出设备的尺寸和特性。缩放后的字形轮廓必须以一个绝对度量系统来描述,也就是要将定义字形轮廓的点转换为设备特定的像素网格中的像素。为了保持轮廓的精度,设备像素网格中的最小单位为最接近1/64像素的值。
FUnit到像素的转换
FUnit转换为像素有两个值需要计算:一是以FUint表示的字形转换后相当于多少像素,二是FUnit坐标系中的点转换为像素坐标系中的点之后的坐标是多少。
对于第一个转换,最终的像素值取决于渲染为多少点、目标设备的分辨率dpi和em方块的FUnit即upem。假设字体文件中的字形宽度为550 FUnit,设备分辨率为72ppi,字体的upem为2048,渲染为18点,那么渲染后字形的像素值为:
550×18×72ppi/(72dpi×2048upem) = 4.83px
换句话说,字形转换后的像素值与其本身的FUnit值、渲染的点数和设备分辨率成正比,与字体的upem成反比。最后,72dpi是一个常量(即1英寸等于72点)。
对于第二个转换,即字形中点的坐标从FUnit转换为像素,首先需要知道转换后每em中点的数量,即ppem(与设备分辨率成正比):
ppem = 渲染点数 × 设备分辨率 / 72dpi
假设要打印为12像素,而打印分辨率为300dpi,那么每个字形的ppem就是:12 × 300 / 72 = 50。也就是每个字形可以用50个(墨)点来呈现。
然后,我们知道有以下等式:
像素坐标/ppem = FUnit坐标/upem
也就是像素坐标与ppem的比,始终等于FUnit坐标与upem的比。所以:
像素坐标 = FUnit坐标 × ppem / upem
假设还是在300dpi的激光打印机上,要打印12点大小的字形,那么其ppem是50。相应地,这个字形轮廓中某个点的坐标如果是(1024, 0),而字体的upem为2048,则这个点对应的像素坐标就是(25, 0)。
字形轮廓适配网格
适配网格是通过执行指令实现的。适配网格的目的是让字形在不同大小和不同设备上都能保留或者呈现原始设计的特征,特别是保证一致的主干高度、均匀的间隔,以及消除像素漏点(dropout)。
为实现这些目标,就要确保将字形像素化时打开某些像素。在这种情况下,可能就需要改变或扭曲原始的轮廓定义以产生高质量的位图。原始字形轮廓的这种变形就叫做网格适配(grid-fitting)。
下图展示了网格适配对原始设计的拉伸效果:


图11 未经网格适配和经过网格适配的轮廓及位图
网格适配就是根据与字形关联的指令拉伸字形的过程。经过网格适配后,构成字形轮廓的点数不变,但这些点的位置(坐标)会发生偏移。
理解指令
TrueType指令集定义了很多指令供设计者使用,以指定如何渲染字形,好在被缩放时保留字体应有的特征。换句话说,指令用于在为了不同大小或设备适配网格时控制字形轮廓。
适配网格意味着移动轮廓上的点,移动的点称为"动过"。使用TrueType字体不一定非要执行指令,如果输出设备的分辨率够高、渲染点数也够大,不运行指令也可以输出高质量的字形。不过,对于渲染点数较小的情况,为保证输出结果的可读性,添加并运行指令则是至关重要的。
TrueType解释器怎么知道如何拉伸字形轮廓以产生可以接受的结果呢?相关信息包含在附加给字体中每个字形的指令里。指令规定了字形在被缩放时需要保留的设计。下图展示了在未运行指令的情况下渲染9点大小的Arial小写字母m时,由于主干要保持在像素中心点,结果会丢掉一条主干。而右侧的图表明,指令将主干与网格对齐,从而保持了主干的完整无缺。
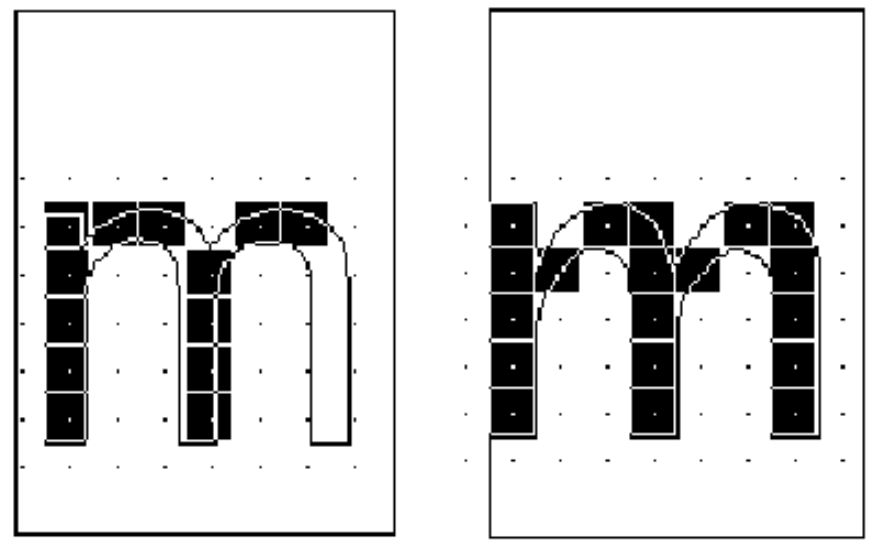
图12 应用指令前后的9点大小的Arial
TrueType解释器
指令由TrueType解释器解释执行。具体来说,解释器会处理指令流或指令序列,而指令会从解释器的栈空间取得参数,然后将执行结果再放回到栈上。也有少数指令负责把数据推到栈上,这些指令从指令流中取得自己的参数。
解释器的所有操作都在Graphics State的上下文中运行。Graphic State是一组变量,这些变量的值用于指导解释器运行并决定特定指令执行的结果。
解释器的操作可以总结如下:
- 解释器从指令流中取得一条指令,即一连串有序指令操作码和数据。操作码以字节为单位,数据可能是单字节也可能是双字节(字)。指令从指令流中取得字数据,也会创建双字节的字。高字节先出现在指令流中,低字节紧随其后。
- 执行指令:如果是推送指令,则从指令流中取得参数。其他指令则从栈中取得数据,而这些指令生成的数据又会推送到栈上。解释器的栈是一个后进先出的数据结构。指令都是从栈的最后一项取得自己需要的数据。指令集中包含对入栈、出栈、清空和复制栈的全部指令。指令执行的效果取决于Graphics State中的变量和值。而指令也可以修改Graphics State的变量。
- 重复以上过程,直至所有指令都执行完毕。
指令在哪
指令可能保存在字体文件的很多地方。比如,可以出现在Font Program和CVT Program中,也可以出现在字形数据里。位于前两个表中的指令适用于整个字体,位于字形数据里的指令只适用于特定的字形。
Font Program中的指令只会在应用程序读取字体时执行一次。这里的指令用于创建函数定义(FDEF)和指令定义(IDEF)。Font Program中的函数和指令定义可在字体文件中任何地方使用。
CVT Program中的指令会在每次字形缩放时执行,但它只用于字体层面的变化,而不管具体字形。具体来说,CVT Program中的指令用于建立Control Value Table中的值。Control Value Table也就是CVT的目的是辅助运行指令时维护字体的一致性。
引用CVT中值的指令称为间接指令,从字形数据中取得值的指令则是直接指令。TrueType字体文件中的CVT值以FUnit表示。当轮廓从FUnit转换为像素时,CVT中的值也会转换。
向CVT中写入值时,可以使用字形坐标系中的值,也可以使用原始FUnit的值。解释器会相应地缩放这些值。而从CVT中读取的值始终都以像素为单位。
Graphics State
Graphics State包含一个表,其中保存着变量及它们的值。所有指令都是在Graphics State的上下文中运行。Graphics State中的所有变量都有默认值,其中一些值可以在CVT Program中修改。但是,在处理单个字形时修改Graphics State变量的值只会对影响相应字形的后续处理。
扫描转换程序
TrueType的扫描转换程序接收字形的轮廓,生成该字形的位图图像。扫描转换程序有两种模式。在第一种模式下,扫描转换程序使用一个简单的算法确定哪些像素属于字形轮廓。
- 规则一:如果像素的中心落在字形的轮廓上,则该像素打开并成为字形的一部分。
- 规则二:如果轮廓恰好落在一个像素的中心,则该像素打开。
如果一个点具有不是零的“缠绕”(winding)值,则该点就被认为是字形内的点。要确定一个点的“缠绕”值,需要从这个点向无穷大方向画一条放射线。从0开始,每当有一个轮廓从右向左或从下向上跨过这条放射线,就减1。这种交叉称为“开转换”(on transition)。反之,每当有一个轮廓从左向右或从上向下跨过这条放射线,就加1。这种交叉称为“关转换”(off transition)。
至于轮廓的方向,可以通过查看点的编号确定。方向始终都从小号到大号。下图说明了如何使用缠绕值来确定一个点是不是在字形内部。
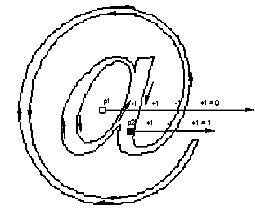
图13 确定一个点的缠绕值
图中点p1一共经历了4次转换(开、关、开、关),因为转换次数是偶数,所以缠绕值为0,换句话说该点不是字形内的点。而p2经历了3次转换(关、开、关),缠绕值为+1,因此点p2是字形内的点。
消除漏点
漏点(dropout)会在字形内部相连部分包含两个黑像素但通过只能连接黑像素的直线却不能连接时发生。
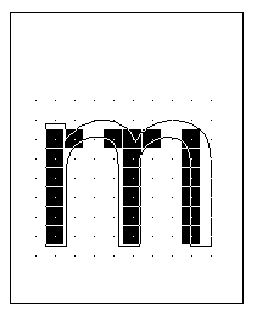
图14 字母m有两个漏点
TrueType指令的设计可以让扫描转换程序开启必要的像素,而不必去管渲染大小或者如何变换。但是,我们毕竟不可能预先知道字形所要发生的所有变换。特别是在ppem较小而字形相对复杂的情况下,像素漏点在所难免。
通过观察连接两个相邻像素中心的线段可以测试漏点。如果这个线段同时与一个开转换和一个关转换相交,则有出现漏点的可能。但是,只有两个轮廓继续沿各自方向前进,并切断了连接相邻像素中心的其他线段时,潜在的漏点才会成为真正的漏点。如果两个轮廓在跨过线段后马上结合,则不会出现漏点,但字形的某个主干可能会变短。
为了避免发生像素漏点,字体制造商可以让扫描转换程序额外使用两个规则。
- 规则三:如果两个相邻像素中心之间的一条线(不管垂直还是水平)同时与一个开转换和一个关转换轮廓相交,且没有任何像素被规则一和规则二打开,则打开最右边的像素(水平线段)或最下方的像素(垂直线段)。
- 规则四:只在两条轮廓线继续沿各自方向分别与其他线段相交时应用规则三。这样不会对“短线”(stub)开启像素。
字体制造商或设计得可以选择基于规则一和规则二进行简单的扫描转换,也可以在必要时使用规则三和规则四。这些选择造成了字体与字体间的差异。但prePromgram中的指令默认会影响整个字体,而个别字形中的变化则只影响该字形。
相关链接
- TrueType fundamentals:https://docs.microsoft.com/zh-cn/typography/opentype/spec/ttch01